Topics
Data mining: Introduction, association rules mining, Naive algorithm, Apriori algorithm, direct hashing and pruning (DHP), Dynamic Item set counting (DIC), Mining frequent pattern without candidate generation (FP, growth), performance evaluation of algorithms
Classification: Introduction, decision tree, tree induction algorithms – split algorithm based on information theory, split algorithm based on Gini index; naïve Bayes method; estimating predictive accuracy of classification method
1. Data Mining
Algo’s DIY
2. Classification
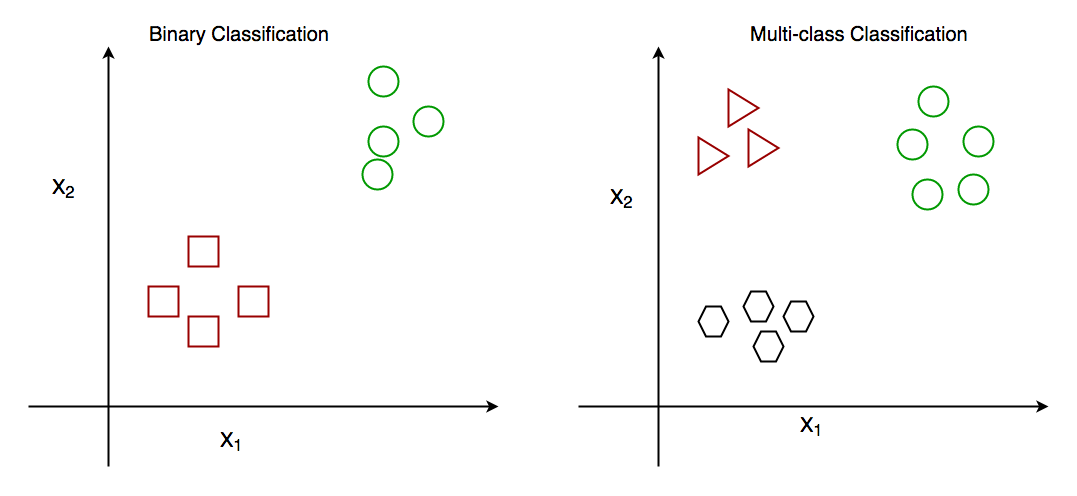
Classification & Clustering, both used for the categorization of objects into one or more classes based on the features.
Classification – Predefined labels assigned to each input. Supervised Learning.
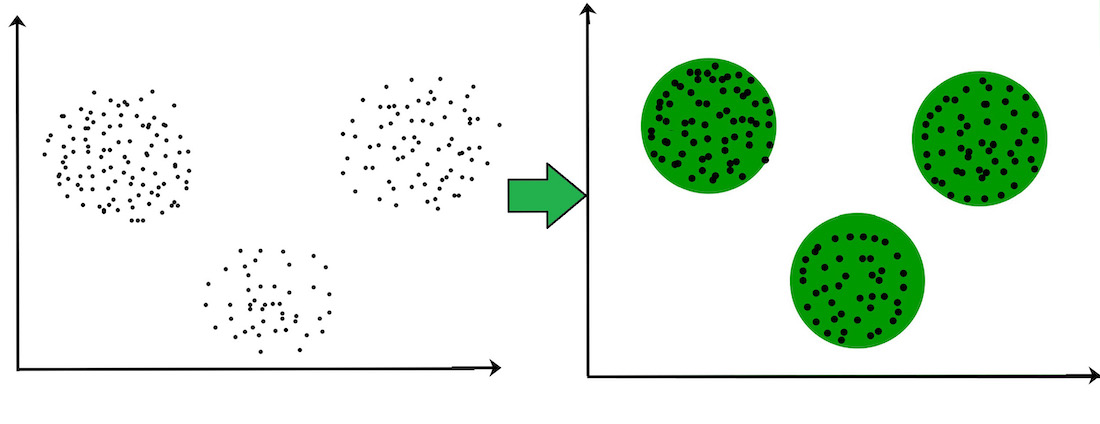
Clustering – No pre-defined labels to input. Unsupervised Learning.
Decision Tree
- Decision Tree is a Supervised Learning Technique (in which machine learn from known datasets, and then predict the output.)
- Used for Regression & Classification (preferred)
- In order to build a tree, we use the CART algorithm, Classification and Regression Tree algorithm.
- Very useful – As Mimics human thinking ability, can be easily understood cause of tree like structure.
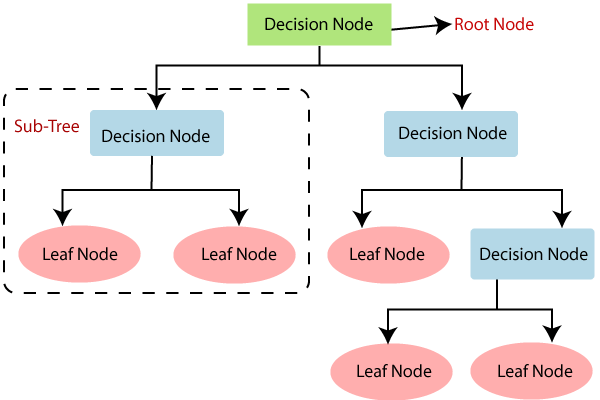
Terminology
- Internal/Decision nodes- Features of a dataset
- Branches - Decision rules
- Leaf Node – Final Outcome.
- Note : Decision nodes to make any decision and have multiple branches, whereas Leaf nodes are the final output of those decisions and do not contain any further branches.
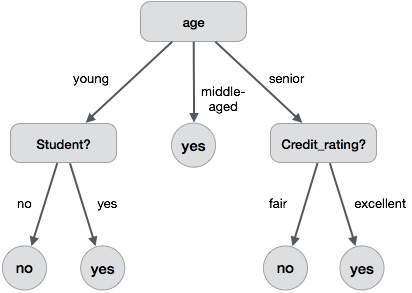
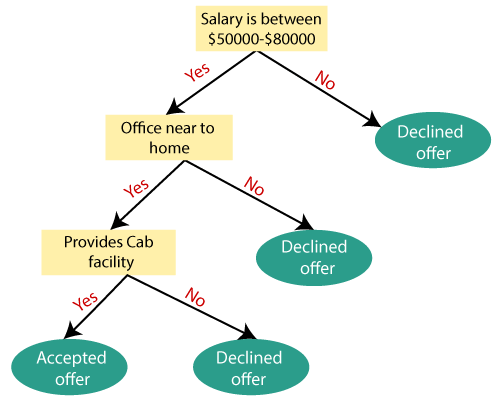
Example
- A customer at a company is likely to buy a computer or not.
Creating Decision Tree
The main issue arises that how to select the best attribute for the root node and for sub-nodes. So, to solve such problems there is a technique which is called as Attribute selection measure or ASM.
In general, two steps are followed :
- Splitting: Process of dividing the decision/root node into sub-nodes according to the given conditions.
- Pruning: Process of removing the unwanted branches from the tree.
Information Gain
- Measurement of changes in entropy after the segmentation of a dataset based on an attribute.
- Calculates how much information a feature provides us.
- Attribute having the highest information gain is split first.
- Formula -
Information Gain= Entropy(S)- [(Weighted Avg) * Entropy(each feature) - Entropy is a measure of impurity in a given attribute.
Entropy(s)= -P(yes)log2 P(yes)- P(no) log2 P(no)
For Calculation refer
Gini Index
- Measure how often a randomly chosen element would be incorrectly identified.
- Low Gini index is preferred over high Gini index.
- Formula

For Calculation refer
Naive Bayes

Comments
Post a Comment